Making Legacy Software Agent-Friendly: Fast Spawn, Branching, and Rollback
Traditional software and cloud services were designed for humans. Creating a database, deploying a service, or warming a cache is typically a low-frequency action — waiting tens of seconds or even minutes is acceptable. Humans read consoles, wait for resources to become ready, manually fix errors, and double-check before touching production.
Agents work differently. An Agent is not "a faster human" — it is a class of software consumer that automatically executes, iterates through trial and error, and explores in parallel. In a single task it might create multiple databases, launch multiple runtimes, run several migrations, try different dependency combinations, and then continue based on error logs. For an Agent, creating a resource is not an ops task — it is part of the inference-and-action loop.
This creates new fundamental requirements: services must be fast to spawn and scale out; instances should be isolated and disposable; state must be saveable during execution; failures must be reversible; and when facing multiple possible paths, the system must be able to fork multiple environments from the same state. Otherwise, every Agent misstep becomes an expensive rebuild — re-installing dependencies, re-importing data, re-starting services, re-running the entire initialization flow.
In other words, an Agent-friendly service is more than "has an API." It needs capabilities akin to a code repository: fast creation, branching, state rewind, and automatic cleanup. APIs solve "can it be called?"; snapshots, branching, and rollback solve "can the Agent afford to make mistakes, compare alternatives, and recover?"

Some Agent-Friendly Services

Neon is a prime example. It turned Postgres into an Agent-first serverless database — 80% of databases on Neon are created automatically by Agents. For a human developer, a database is typically a long-lived resource created once early in a project and maintained thereafter. For an Agent, every generated application, every preview environment, every schema migration attempt may need its own isolated database. Neon's API-first provisioning lets databases be embedded in an Agent's execution path rather than requiring a human to step out of the workflow.
More importantly, Neon made Postgres a versioned data service. Copy-on-write branching lets an Agent fork from an existing database state to test schema migrations, data fixes, or app versions without affecting the primary database. Snapshot, point-in-time recovery, and restore provide database timeline capabilities. If an Agent generates an erroneous migration, it does not need to rebuild the database from scratch — it can rewind to a prior state and try again.
The significance goes beyond "creating databases faster." It changes the relationship between the database and the Agent: Postgres is no longer a long-lived resource requiring human ops, but a data service the Agent can dynamically create, branch, rollback, and destroy. And the trend is clear — the share of Agent-driven resource usage is growing rapidly.
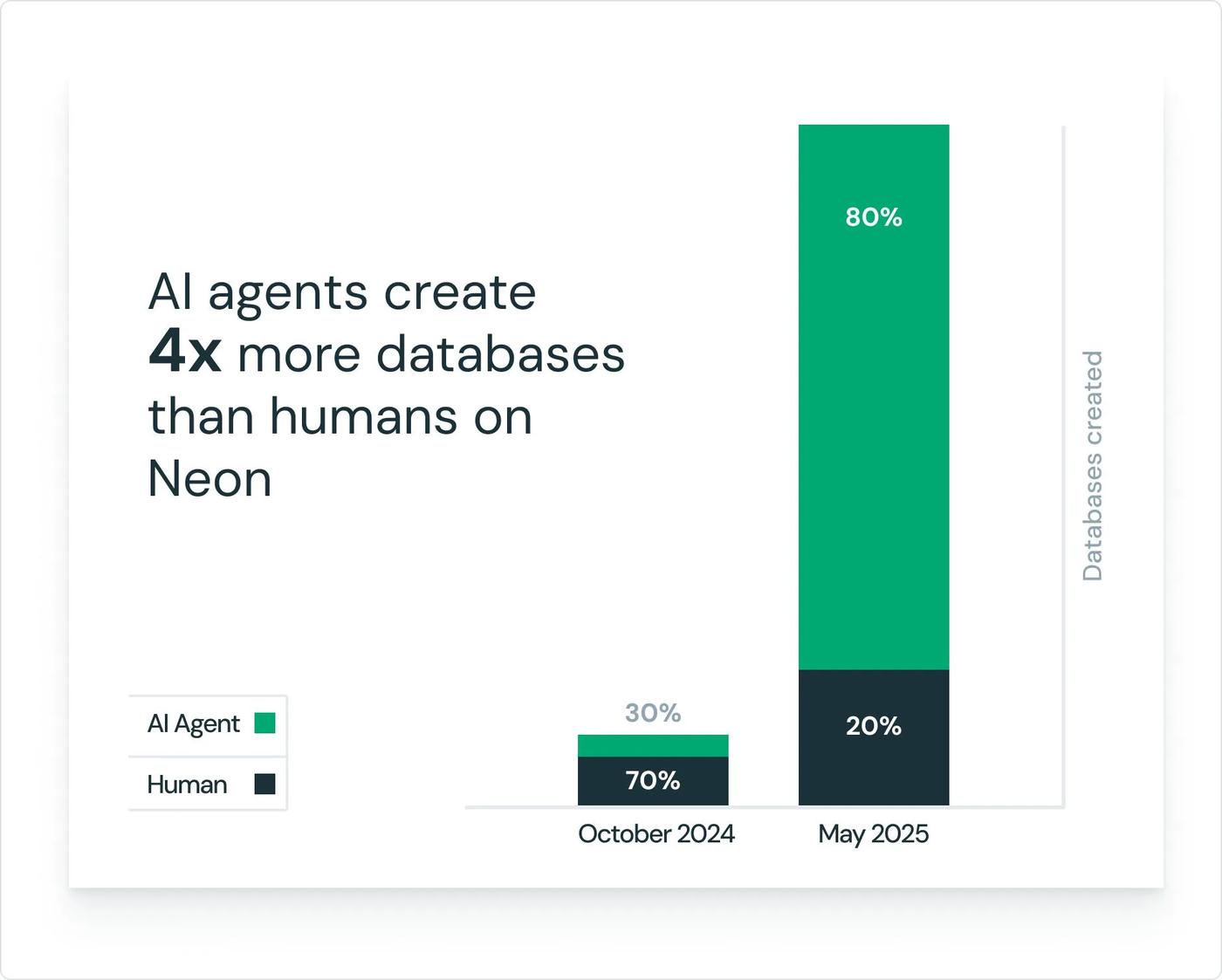
Neon's rapidly growing Agent-driven market share and its Agent-native product capabilities caught Databricks' attention. In May 2025, Databricks acquired Neon for $1 billion. "The era of AI-native, agent-driven applications is reshaping what a database must do," said Ali Ghodsi, Co-Founder and CEO at Databricks. "Neon proves it: four out of every five databases on their platform are spun up by code, not humans. By bringing Neon into Databricks, we're giving developers a serverless Postgres that can keep up with agentic speed, pay-as-you-go economics and the openness of the Postgres community."
Turso represents another direction: Agent-friendly SQLite / edge databases. It emphasizes that every user, agent, and tenant can have its own database. SQLite/libSQL's lightweight model naturally suits a large number of small databases, while Turso adds edge replicas, sync, API management, Copy-on-Write branching, and rollback. For Agents, this means memory, task state, and local RAG data don't have to live in one central store — they can become "one branchable mini-database per Agent."
Upstash leans toward Agent-ifying middleware services. Redis, queues, vector search, and workflow capabilities traditionally require long-term maintenance. Upstash turns them into on-demand Agent components via REST API, URL + Token, per-request billing, and scale-to-zero. It may not emphasize branching or rollback, but it excels at temporary state, caching, task queues, async tool calls, and RAG storage.
These examples share a common trend: traditional services are evolving from "resources used by humans" into "runtime units that Agents can automatically create, replicate, observe, and reclaim."
CubeSandbox: Generalizing This Capability to Any Software Service
Neon and Turso solve branching and rollback for databases; Upstash solves fast provisioning for middleware. But the real software world goes far beyond these. Redis, browsers, development environments, backend services, test systems, and complex dependency stacks can all become Agent operation targets.
The value of CubeSandbox lies in its attempt to generalize "fast spawn, branching, and rollback" from any single service into a universal runtime capability. That is, even if a traditional service inherently lacks fast startup, built-in branching, or rollback, as long as it can run inside a sandbox, it gains these capabilities.
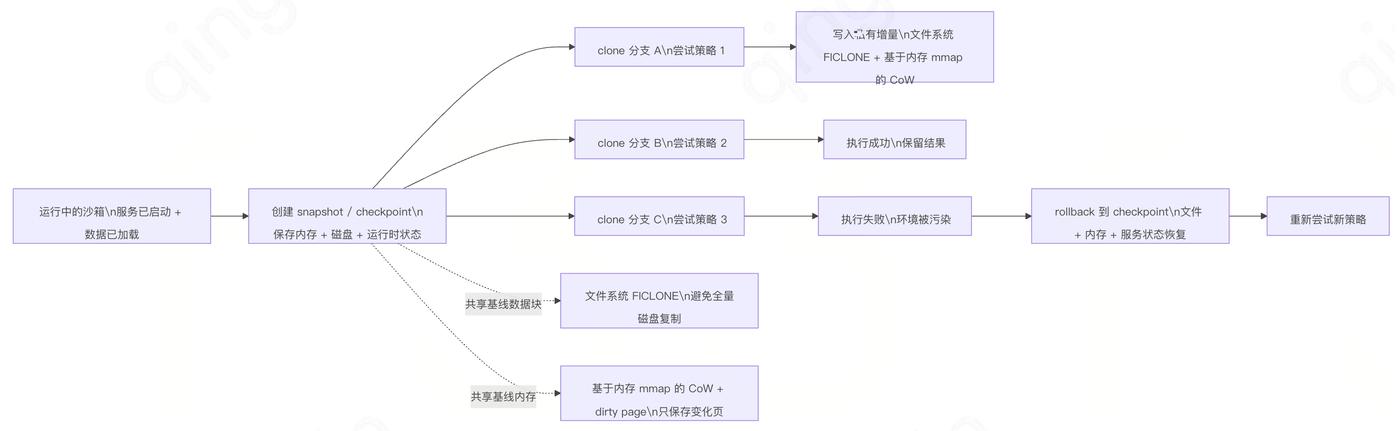
Its core is not simply launching a container. It combines MicroVM isolation with resource pooling, snapshots, filesystem FICLONE, memory-mmap-based CoW, and incremental memory snapshots to let running service state be saved, replicated, and restored in under a hundred milliseconds. "State" here means not just files, but also processes, in-memory data structures, already-running services, and half-completed task contexts.
Why is it so fast?
First, fast startup comes from pre-built baselines and snapshot cloning. The traditional approach requires booting from scratch, loading images, and starting services; CubeSandbox can start directly from a prepared state, skipping the entire boot path.
Second, disk cloning is not a full filesystem copy. CubeSandbox leverages the filesystem's FICLONE mechanism so that new instances initially share existing snapshot data blocks; only on write does a private copy get created. Clone is therefore a metadata operation, not a full disk copy.
Third, incremental memory snapshots. Consecutive snapshots don't repeatedly persist all memory — dirty page tracking saves only changed pages. At runtime, mmap-based CoW lets multiple branches share baseline memory state, forking only on modification.
Fourth, rollback is not destroy-and-rebuild. It restores the current sandbox in-place to a checkpoint's memory and filesystem state, avoiding re-scheduling, re-connecting, and re-starting services. Failure recovery shifts from "rebuild the environment" to "rewind the state."
For a deeper technical walkthrough, see:
- From Serverless to Agent: Design Thinking Behind Cube
- Cube Sandbox v0.3.0: A Time Machine and a Cloning Booth for Your AI Agents
- CubeSandbox Performance Benchmark Report
The diagram below summarizes the relationship between snapshot, clone, and rollback in CubeSandbox: snapshot freezes a running state into a checkpoint; clone forks multiple branches from that checkpoint (or a running sandbox); rollback rewinds a failed branch back to the checkpoint in-place.
Hands-On Examples
The following three demo programs showcase CubeSandbox's branching exploration, instant rollback, and how to easily turn a traditional service into an Agent-friendly service with "fast spawn and clone" capabilities.
Prerequisites
Deploy a CubeSandbox service following the CubeSandbox Quick Start Guide
Our examples use a Redis service. There are two ways (either works) to build a Redis service template:
2.1 Build a Redis service template yourself following the Custom Image Guide
2.2 Use our pre-built Redis image:
bashcubemastercli tpl create-from-image \ --image cube-sandbox-image.tencentcloudcr.com/demo/redis-envd:latest \ --writable-layer-size 1G \ --expose-port 6379 \ --expose-port 49983 \ --probe 49983 \ --cpu 1000 \ --memory 1000This will produce a Template ID. Record it, e.g.
tpl-xxxyyy:bashexport CUBE_TEMPLATE_ID=tpl-xxxyyyOn the CubeSandbox host, clone the example repository. All examples run on the host:
bashgit clone https://github.com/kinwin-ustc/cube-sandbox-examples.git
1. Sub-100ms Branch Cloning
This example is from examples/redis-clone. It first creates a source sandbox, starts Redis inside it along with a background pusher.sh program. This program writes a random value to the Redis test list every second, exiting after 10 writes. After about 4 seconds, the Python code calls src.clone(n=8, concurrency=8) to clone 8 branches from the running source sandbox at once.
How to run:
cd examples/redis-clone
python3 redis_clone_demo.pySample output:
[host] creating source sandbox from tpl-e48c5119a5714f3aa7853779 ...
[host] source sandbox: 2626f7d437484eafb3318f41eeaffeb3
[host] ensuring redis-server is running ...
[host] uploaded pusher program -> /tmp/pusher.sh
[host] pusher launched in background
[host] letting the program run ~4s ...
[host] t=4s -> cloning 8 sandboxes via sb.clone(n=8)
[host] clone took 0.387s (0.048s per clone)!!
[host] cloned 8 sandboxes:
clone[0] 88b9dada96464f34b75ac51e8b7ce9ec
clone[1] 9351f4e3af2a48fcb2eac73704f04d13
...
[host] waiting for all programs to finish ...
===== program output of all sandboxes =====
2626f7d437484eafb3318f41eeaffeb3 test YHATC7qZ AmnOf02A NH2cEZIQ C3cYqTZe C4FgZaOs ...
88b9dada96464f34b75ac51e8b7ce9ec test YHATC7qZ AmnOf02A NH2cEZIQ C3cYqTZe KQ4SD8cJ ...
...
===========================================What this shows: 8 clones took 0.387s total, averaging 0.048s per clone. More importantly, the first 4 elements of the Redis list are identical across the source and cloned sandboxes — the clone inherited Redis's in-memory state at the moment of cloning. But from the 5th element onward, each branch diverges, because after cloning each branch independently continues running its background process. This is not "starting 8 new Redis instances" — it's forking 8 futures from a single runtime state.
2. Sub-100ms Event-Level Snapshot Rollback
This example is from examples/rollback-fuzz. There is a target file /workspace/rollback_test in the sandbox. The program builds 10 random commands targeting this file, one of which deletes it. Every second, a random command is selected and executed, and the command is appended to the command_records list in Redis. Before each random bash command, the program creates a snapshot; if after execution it detects that the target file was deleted, it immediately rolls back to the pre-execution checkpoint and exits.
How to run:
cd examples/rollback-fuzz
python3 rollback_fuzz_demo.pyCore flow:
snapshot = sb.create_snapshot()
# Execute a random command and record it in Redis
# If /workspace/rollback_test is deleted, rollback to snapshot
sb.rollback(snapshot.snapshot_id)Sample output:
[host] running, picking one command every 1s ...
[step 001] snap=snap-c6c46e31cb484bc885ce437a snapshot took 0.058s
wrote 9.7 MiB cmd=cat /workspace/rollback_test > /dev/null
[step 002] snap=snap-73e23f6c01b24a36b806c405 snapshot took 0.105s
wrote 6.7 MiB cmd=date +%s%N >> /workspace/rollback_test
[step 003] snap=snap-d969da92e63745b7a101f010 snapshot took 0.098s
wrote 6.6 MiB cmd=rm -f /workspace/rollback_test
[host] !! target file deleted by: rm -f /workspace/rollback_test
[host] command_records BEFORE rollback (3 items):
[00] cat /workspace/rollback_test > /dev/null
[01] date +%s%N >> /workspace/rollback_test
[02] rm -f /workspace/rollback_test
[host] rolling back to snapshot snap-d969da92e63745b7a101f010 ...
[host] rollback took 0.121s!!
[host] target file restored: True
[host] command_records AFTER rollback (2 items):
[00] cat /workspace/rollback_test > /dev/null
[01] date +%s%N >> /workspace/rollback_testWhat this shows: Each snapshot before a command takes ~100ms, and every snapshot is incremental (less than 10 MiB written). Rollback restores not just the filesystem but also memory state. Before rollback, Redis had 3 commands recorded including the delete; after rollback, the target file is restored and the delete command record is gone — only the first 2 remain. CubeSandbox rolled back files, memory, and the Redis runtime state all the way to the checkpoint. For an Agent, a mistake no longer means rebuilding the environment — it can rewind in roughly a hundred milliseconds.
3. Wrapping Redis as a Fast-Spawn, Cloneable Agent Redis Service
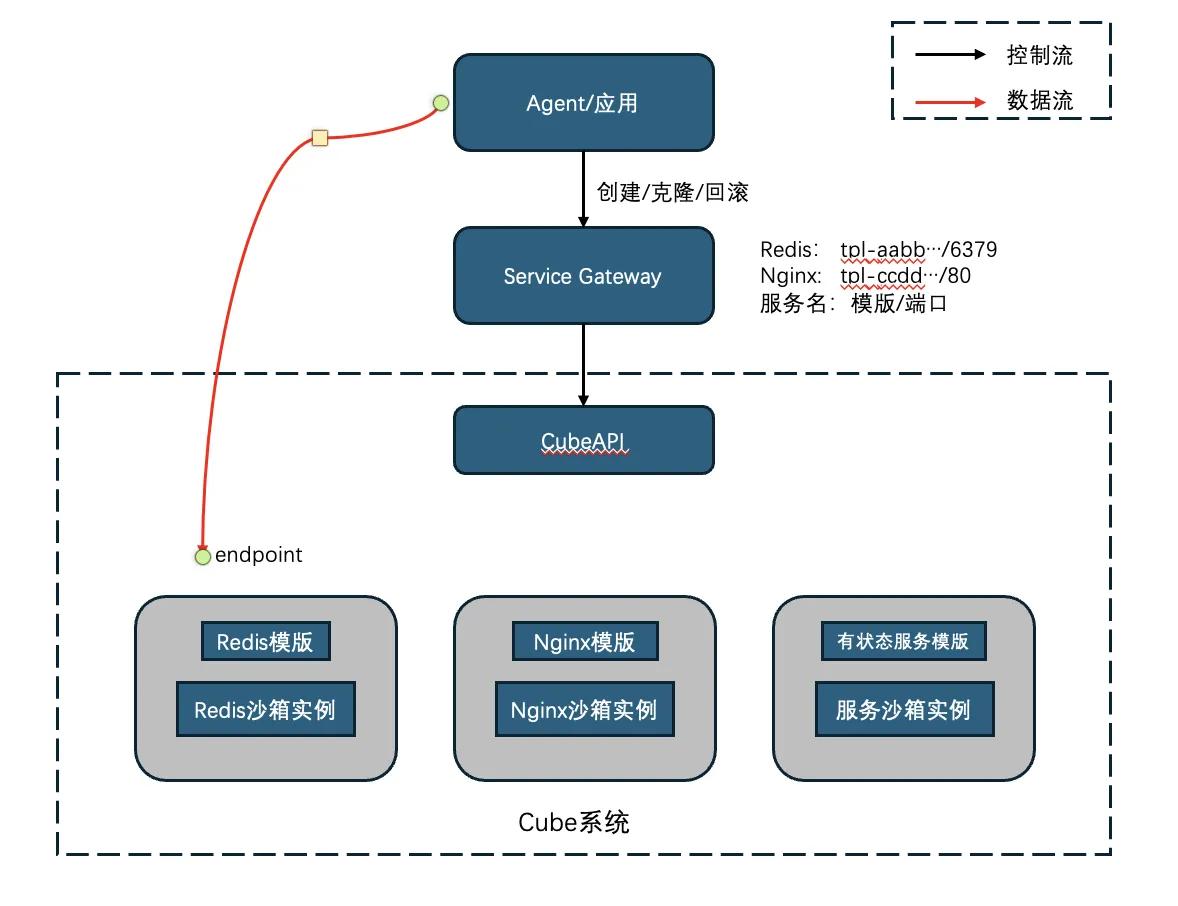
This example is from examples/cube-service-gateway. Based on a pre-built Redis sandbox template, it connects to CubeSandbox via cube-service-gateway: the Agent simply calls create redis, and the gateway maps the redis -> template_id + service_port configuration to spin up a Redis sandbox via the Cube API and returns the accessible endpoint.
This step is significant: traditional Redis is a stateful service requiring human provisioning, deployment, configuration, and maintenance. After gateway wrapping, it becomes an Agent Redis service with "fast spawn, fast clone, and extensible rollback support." The minimal example demonstrates create / clone / destroy, and the previous rollback example already proved CubeSandbox can restore Redis runtime state. Extending the gateway to expose snapshot / rollback actions would make rollback a service API as well.
This architecture is not limited to Redis. As long as you prepare a template for any stateful service — Redis, MySQL, Postgres, Nginx, message queues, or vector databases — and declare the service name, template ID, and port in the gateway config, CubeSandbox provides the corresponding service instance. In other words, Cube provides a "templated stateful service" lifecycle foundation: fast creation, branch cloning, checkpoint saving, failure rollback, and eventual teardown.
Architecture diagram:
How to run:
cd examples/cube-service-gateway
cp config.example.json config.json
python3 server.py config.json
# In another terminal, create a Redis service
python3 client.py create redis
# With the sandbox_id, clone the Redis service
python3 client.py clone <sandbox_id>Key configuration mapping:
{
"templates": {
"redis": {
"template_id": "tpl-e48c5119a5714f3aa7853779",
"service_port": 6379
},
"nginx": {
"template_id": "tpl-13df4e20518c465a90c1d7e1",
"service_port": 80
}
}
}Sample output:
$ python3 client.py create redis
{
"sandbox_id": "0f067f5e61ad477fa32d0df45434d51d",
"name": "redis",
"service_port": 6379,
"endpoint": "10.206.0.4:20006"
}
elapsed: 77.1 ms
$ redis-cli -h 10.206.0.4 -p 20006
10.206.0.4:20006> set name rony
OK
10.206.0.4:20006> get name
"rony"
$ python3 client.py clone 0f067f5e61ad477fa32d0df45434d51d
{
"sandbox_id": "40e42e1e7fe34ae4b995271d39166b2e",
"name": "redis",
"service_port": 6379,
"endpoint": "10.206.0.4:20008"
}
elapsed: 314.2 ms
$ redis-cli -h 10.206.0.4 -p 20008
10.206.0.4:20008> keys *
1) "name"
10.206.0.4:20008> get name
"rony"What this shows: create redis returns an accessible Redis in 77.1ms. After writing name=rony, the cloned Redis still reads "rony" — clone took 314.2ms. Redis data state was copied to the new instance. For an Agent, this isn't just "spinning up a cache service" — it's getting a Redis workspace that can fork from any known state.
Note: Cloned instances inherit the source's network connections, but these connections can no longer send or receive packets. It's best to explicitly handle stale connections or wait for them to time out.
This pattern extends to other stateful services in just two steps:
- Build a template containing your service following the Custom Image Guide, and note the template ID:
tpl-abcdeeff - Edit the cube-service-gateway config to add the new service template:
{
"templates": {
"redis": {
"template_id": "tpl-e48c5119a5714f3aa7853779",
"service_port": 6379
},
"new_service": {
"template_id": "tpl-abcdeeff",
"service_port": <service-port>
}
}
}The service itself remains traditional software. But once connected to CubeSandbox, its lifecycle becomes Agent-friendly: fast spawn, stateful clone, failure rollback, and teardown when the task ends.
Conclusion
What Agents demand of software services is, at its core, a shift in state lifecycle management. We used to care about whether a service ran stably; now we must also ask whether it can be created quickly, branched from any state, rolled back on failure, and exist cheaply at scale.
Neon, Turso, and Upstash show that various categories of software are already reshaping their product form around how Agents work. CubeSandbox goes further: it pushes fast startup, snapshots, cloning, and rollback down into a general-purpose runtime environment, allowing traditional services to easily gain "branching" and "time machine" capabilities.
Check out the CubeSandbox project: https://github.com/TencentCloud/CubeSandbox