让传统软件服务适配 Agent:从快速创建到分支、克隆与回滚
过去的软件和云服务,主要是为人设计的。人类用户创建一个数据库、部署一个服务、初始化一个缓存,通常是低频动作;即使等待几十秒甚至几分钟,也可以接受。人会阅读控制台、等待资源就绪、手动修复错误,并且在真正影响生产环境前反复确认。
Agent 的使用方式不同。Agent 不是"更快的人类用户",而是一类会自动执行、反复试错、并行探索的软件使用者。它可能在一次任务里创建多个数据库、启动多个运行环境、执行多轮迁移、尝试不同依赖组合,再根据错误日志继续修改。对 Agent 来说,创建资源不是运维动作,而是推理和执行循环的一部分。
这带来了新的基础需求:服务必须能被快速、大量创建;每个实例最好是隔离的、可丢弃的;执行过程中要能保存状态;失败后要能回滚;面对多个可能路径时,要能从同一个状态分支出多个环境。否则,Agent 的每一次试错都会变成昂贵的重建过程:重新安装依赖、重新导入数据、重新启动服务、重新走一遍初始化流程。
换句话说,Agent 友好的服务不只是"有 API",而是要具备类似代码仓库的能力:快速创建、分支克隆、状态回退、自动清理。API 解决的是"能不能调用",而快照、分支和回滚解决的是"Agent 能不能低成本地犯错、比较和恢复"。

一些对 Agent 友好的服务

Neon 是一个典型例子。它把 Postgres 做成面向 Agent 的 Serverless 数据库,Neon 上 80% 的数据库都由 Agent 自动生成。对人类开发者来说,数据库通常是项目早期创建一次、后续长期维护的资源;但对 Agent 来说,每生成一个应用、每创建一个预览环境、每尝试一次 schema 变更,都可能需要一个独立数据库。Neon 通过 API-first 的 provisioning,让数据库可以嵌入 Agent 的执行链路,而不是要求用户跳出流程手动开通。
更关键的是,Neon 把 Postgres 做成了可版本化的数据服务。copy-on-write branching 让 Agent 可以从已有数据库状态拉出分支,测试 schema migration、数据修复或应用版本,而不影响主库;snapshot、point-in-time recovery 和 restore 则提供了数据库时间线能力。Agent 如果生成了错误 migration,不必从零重建数据库,可以回到之前状态重新尝试。
这背后的意义不只是"创建数据库更快"。它改变了数据库和 Agent 的关系:Postgres 不再只是一个需要人运维的长期资源,而变成 Agent 可以动态创建、分支、回滚和销毁的数据服务。而从趋势上来看,Agent 自行使用资源的比重正在快速增长。
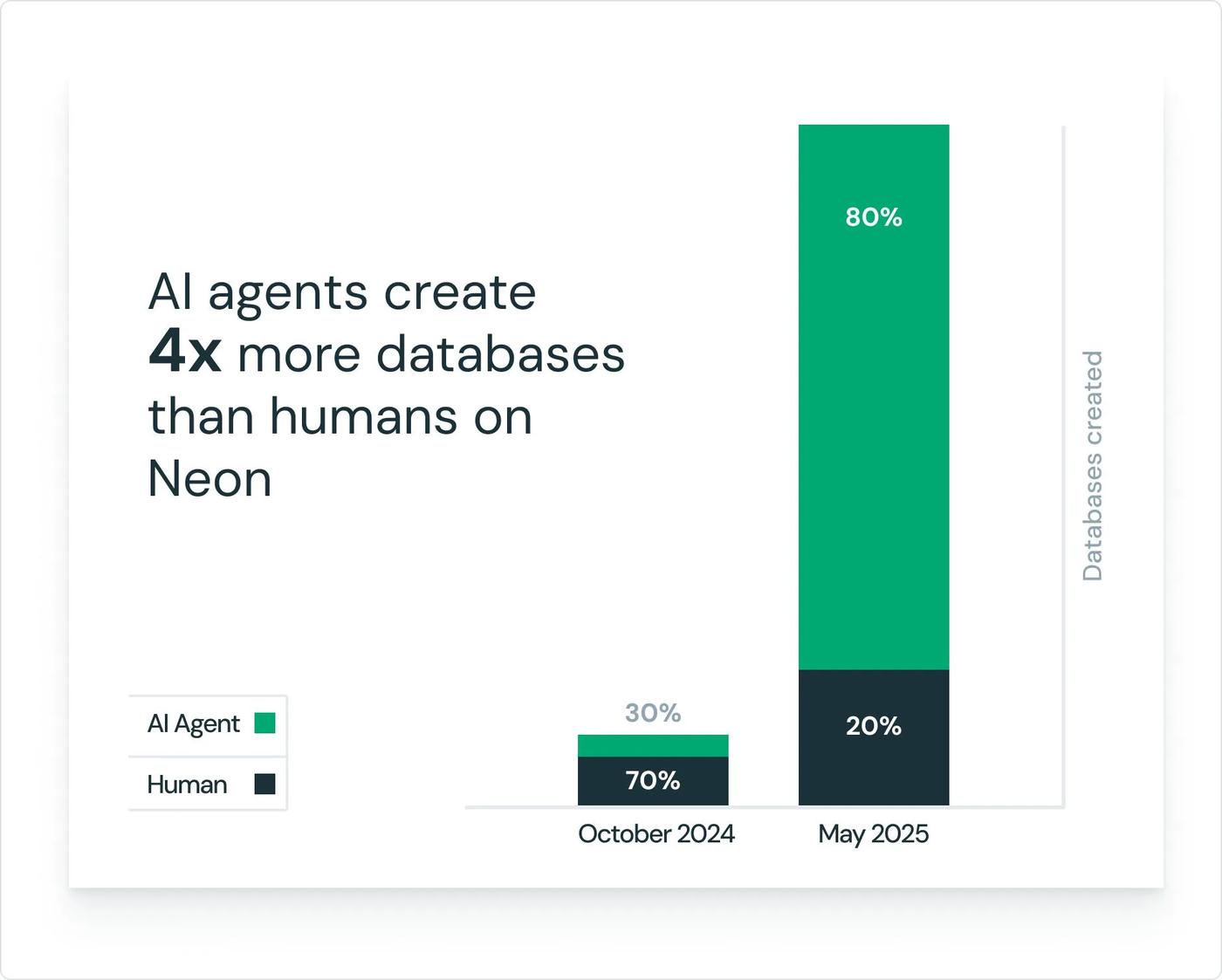
Agent 快速增长的市场份额和 Neon 本身具有的这些为 Agent 而生的产品能力也被 Databricks 所需要,2025 年 5 月,Databricks 以 10 亿美金收购 Neon。"The era of AI-native, agent-driven applications is reshaping what a database must do," said Ali Ghodsi, Co-Founder and CEO at Databricks。"Neon proves it: four out of every five databases on their platform are spun up by code, not humans. By bringing Neon into Databricks, we're giving developers a serverless Postgres that can keep up with agentic speed, pay-as-you-go economics and the openness of the Postgres community."
Turso 代表了另一类方向:Agent 友好的 SQLite / 边缘数据库。它强调每个 user、agent、tenant 都可以拥有独立数据库。SQLite/libSQL 的轻量模型天然适合大量小数据库,而 Turso 又补上了边缘副本、同步、API 管理、Copy-on-Write branching 和 rollback。对于 Agent 来说,这意味着 memory、任务状态、局部 RAG 数据不一定要集中在一个中心库里,而可以变成"每个 Agent 一个可分支的小数据库"。
Upstash 则更偏向中间件服务的 Agent 化。Redis、队列、向量检索、Workflow 这些能力过去通常需要长期维护;而 Upstash 通过 REST API、URL + Token、按请求计费、scale-to-zero,把它们变成 Agent 可按需申请的组件。它不一定强调分支回滚,但非常适合临时状态、缓存、任务队列、异步工具调用和 RAG 存储。
这些案例背后有共同趋势:传统服务正在从"人使用的资源"变成"Agent 可自动创建、复制、观察和回收的运行单元"。
CubeSandbox:把这种能力泛化到任意软件服务
Neon、Turso 解决的是数据库服务的分支和回滚;Upstash 解决的是中间件的快速供给。但真实软件世界远不止这些。Redis、浏览器、开发环境、后端服务、测试系统、复杂依赖环境,都可能成为 Agent 的操作对象。
CubeSandbox 的价值在于,它试图把"快速创建、分支、回滚"从某个具体服务,泛化成一种通用运行环境能力。也就是说,哪怕某个传统服务本身没有快速启动,内建 branching 和 rollback,只要它能运行在沙箱里,就会获得类似能力。
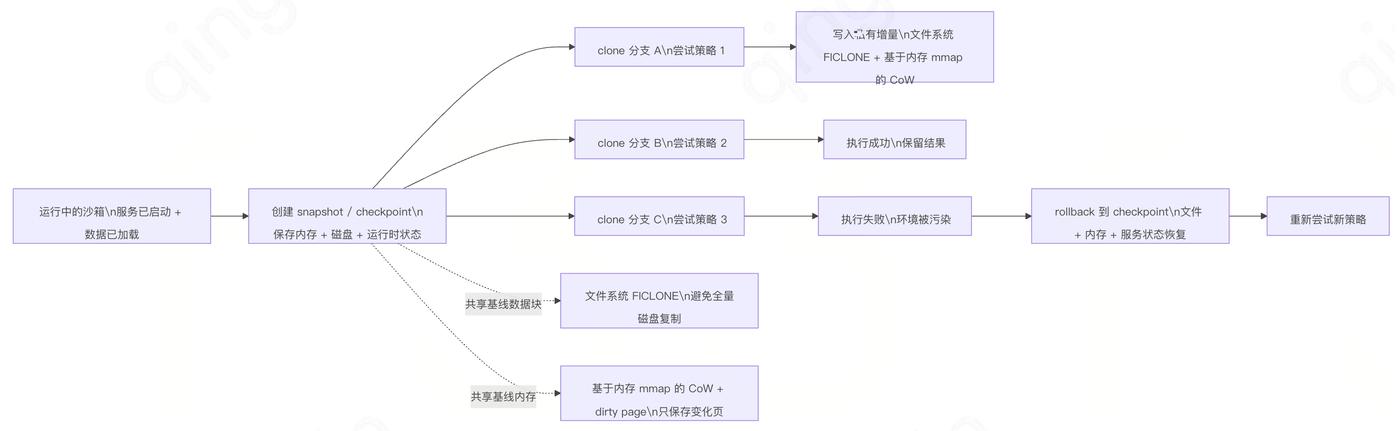
它的核心不是简单地启动一个容器,而是在 MicroVM 隔离之上,结合资源池、快照、文件系统 FICLONE 机制、基于内存 mmap 的 CoW、增量内存快照等机制,让运行中的服务状态可以在百毫秒级被保存、复制和恢复。这里的"状态"不只是文件,还包括进程、内存里的数据结构、已经启动的服务,以及执行到一半的任务上下文。
为什么它能这么快?
第一,快速启动来自预置基线和快照克隆。传统方式要从零启动系统、加载镜像、启动服务;而 CubeSandbox 可以从已经准备好的状态直接开始,跳过整个启动路径。
第二,磁盘克隆不是完整复制文件系统。CubeSandbox 利用文件系统的 FICLONE 机制,让新实例先共享已有快照的数据块;只有发生写入时,才生成私有副本。因此 clone 只是一次元数据操作,而不是整盘复制。
第三,增量内存快照。连续 snapshot 不需要反复持久化全量内存,而是通过 dirty page 追踪,只保存变化页。运行时再结合基于内存 mmap 的 CoW,让多个分支共享基线内存状态,变更时才分叉。
第四,rollback 不是销毁重建。它把当前沙箱原地恢复到某个 checkpoint 的内存和文件系统状态,避免重新调度、重新连接、重新启动服务。失败恢复从"重新搭环境"变成"状态回退"。
更进一步的技术解读可以参考以下文章:
- 从 Serverless 到 Agent:Cube 系统的一些设计思考
- Cube Sandbox v0.3.0 来了:让 AI Agent 拥有"时光机"和"分身术"
- CubeSandbox 性能测试报告
下面这张图可以概括 CubeSandbox 中 snapshot、clone 和 rollback 的关系:snapshot 把某一刻的运行态固定成 checkpoint;clone 从这个 checkpoint 或运行中沙箱派生多个分支;rollback 则把失败分支原地拉回到 checkpoint。
具体例子
以下给出三个示例程序,分别展示 CubeSandbox 的分支探索能力、即时回滚能力,以及如何利用 CubeSandbox 简单地将传统服务变成具备"极速拉起,分支克隆"能力的 Agent 服务。
准备工作
部署一个 CubeSandbox 服务,参照 CubeSandbox 快速部署指南
在我们的示例中,会使用到 Redis 的服务,有两种方法(任何一种都可以)构建这个 Redis 服务的模版:
2.1 参照自定义镜像自行构建一个 Redis 服务模版
2.2 使用我们制作好的 Redis 镜像:
bashcubemastercli tpl create-from-image \ --image cube-sandbox-image.tencentcloudcr.com/demo/redis-envd:latest \ --writable-layer-size 1G \ --expose-port 6379 \ --expose-port 49983 \ --probe 49983 \ --cpu 1000 \ --memory 1000最终会得到一个 Template ID,把这个 Template ID 记录下来,假设为
tpl-xxxyyy:bashexport CUBE_TEMPLATE_ID=tpl-xxxyyy在 CubeSandbox 宿主机上执行以下命令克隆示例代码仓库,以下所有示例的代码都在 CubeSandbox 宿主机上运行:
bashgit clone https://github.com/kinwin-ustc/cube-sandbox-examples.git
1. 百毫秒分支克隆
这个例子来自 examples/redis-clone。它先创建一个源沙箱,在里面启动 Redis 和一个后台 pusher.sh 程序。这个程序每秒向 Redis 的 test list 写入一个随机值,写入 10 次后退出;运行约 4 秒后,Python 代码调用 src.clone(n=8, concurrency=8),一次性从运行中的源沙箱克隆 8 个分支。
如何执行:
cd examples/redis-clone
python3 redis_clone_demo.py执行结果摘录:
[host] creating source sandbox from tpl-e48c5119a5714f3aa7853779 ...
[host] source sandbox: 2626f7d437484eafb3318f41eeaffeb3
[host] ensuring redis-server is running ...
[host] uploaded pusher program -> /tmp/pusher.sh
[host] pusher launched in background
[host] letting the program run ~4s ...
[host] t=4s -> cloning 8 sandboxes via sb.clone(n=8)
[host] clone took 0.387s (0.048s per clone)!!
[host] cloned 8 sandboxes:
clone[0] 88b9dada96464f34b75ac51e8b7ce9ec
clone[1] 9351f4e3af2a48fcb2eac73704f04d13
...
[host] waiting for all programs to finish ...
===== program output of all sandboxes =====
2626f7d437484eafb3318f41eeaffeb3 test YHATC7qZ AmnOf02A NH2cEZIQ C3cYqTZe C4FgZaOs ...
88b9dada96464f34b75ac51e8b7ce9ec test YHATC7qZ AmnOf02A NH2cEZIQ C3cYqTZe KQ4SD8cJ ...
...
===========================================结果说明:8 个克隆总耗时 0.387s,平均每个 clone 0.048s。更重要的是,源沙箱和克隆沙箱的 Redis list 前 4 个元素完全一致,说明 clone 发生时继承了 Redis 的内存状态;但第 5 个元素之后各分支开始不同,说明克隆之后每个分支都在独立继续运行后台进程。也就是说,这不是"重新启动 8 个 Redis",而是从同一个运行时状态分叉出 8 个未来。
2. 百毫秒的事件级快照回滚
这个例子来自 examples/rollback-fuzz。沙箱里有一个目标文件 /workspace/rollback_test,构建 10 条针对这个文件的随机命令,其中有一条命令是删除这个文件,每隔 1s 从 10 条命令中随机抽取一个命令执行,并将执行的命令 append 到 Redis 中的 command_records list。程序每次随机执行 bash 命令前,都会先创建 snapshot;如果执行命令后发现目标文件被删除,就立刻 rollback 到执行该命令前的 checkpoint,并退出程序。
如何执行:
cd examples/rollback-fuzz
python3 rollback_fuzz_demo.py核心流程是:
snapshot = sb.create_snapshot()
# 执行随机命令,并把命令记录写入 Redis
# 如果发现 /workspace/rollback_test 被删除,则回滚到 snapshot
sb.rollback(snapshot.snapshot_id)执行结果摘录:
[host] running, picking one command every 1s ...
[step 001] snap=snap-c6c46e31cb484bc885ce437a snapshot took 0.058s
wrote 9.7 MiB cmd=cat /workspace/rollback_test > /dev/null
[step 002] snap=snap-73e23f6c01b24a36b806c405 snapshot took 0.105s
wrote 6.7 MiB cmd=date +%s%N >> /workspace/rollback_test
[step 003] snap=snap-d969da92e63745b7a101f010 snapshot took 0.098s
wrote 6.6 MiB cmd=rm -f /workspace/rollback_test
[host] !! target file deleted by: rm -f /workspace/rollback_test
[host] command_records BEFORE rollback (3 items):
[00] cat /workspace/rollback_test > /dev/null
[01] date +%s%N >> /workspace/rollback_test
[02] rm -f /workspace/rollback_test
[host] rolling back to snapshot snap-d969da92e63745b7a101f010 ...
[host] rollback took 0.121s!!
[host] target file restored: True
[host] command_records AFTER rollback (2 items):
[00] cat /workspace/rollback_test > /dev/null
[01] date +%s%N >> /workspace/rollback_test结果说明:每次执行命令前打一个快照,snapshot 耗时 100ms 左右,每次做快照都是增量快照,写入内存小于 10MB;rollback 不止恢复了文件系统,还恢复了内存状态。回滚前,Redis 里已经记录了 3 条命令,其中包含删除文件的命令;回滚后,目标文件恢复,Redis 里的删除命令记录也消失,只剩前 2 条。这说明 CubeSandbox 把文件、内存、Redis 运行时状态一起恢复到了 checkpoint。对 Agent 来说,一次错误操作不再意味着重建环境,而是可以在约百毫秒量级回到失败前。
3. 把 Redis 封装成可快速创建和克隆的 Agent Redis 服务
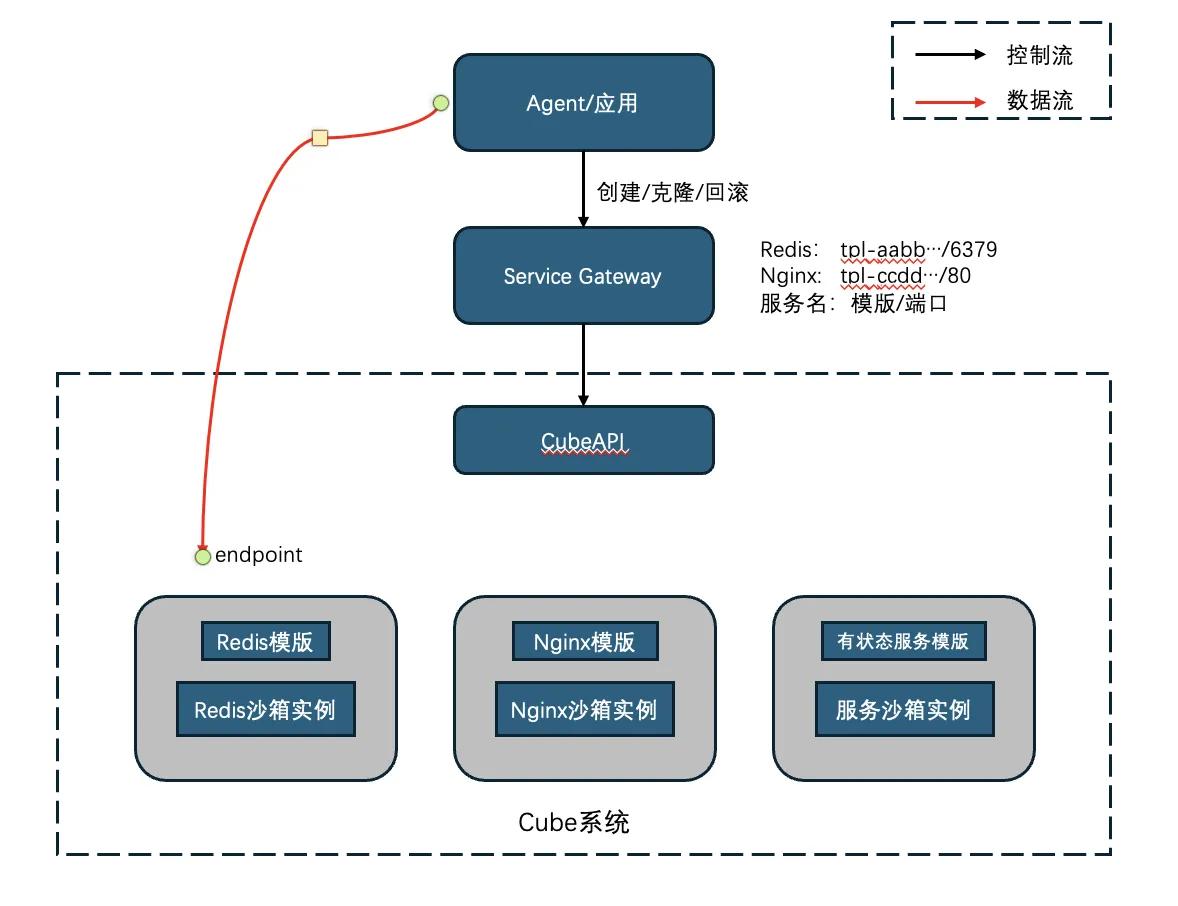
这个例子来自 examples/cube-service-gateway。它基于一个已经准备好的 Redis 沙箱模板,通过 cube-service-gateway 接入 CubeSandbox:Agent 只需要调用 create redis,gateway 就会根据配置里的 redis -> template_id + service_port 映射,通过 Cube API 拉起一个 Redis 沙箱,并返回可访问端点。
这一步的意义很大:传统 Redis 原本是一个需要人申请、部署、配置和维护的有状态服务;经过 gateway 封装后,它变成了一个具备"快速拉起、快速克隆、可扩展支持回滚"的 Agent Redis 服务。最小示例中 gateway 已经演示了 create / clone / destroy,而前一个 rollback 例子已经证明 CubeSandbox 可以恢复 Redis 运行态;因此在同一架构下继续向 gateway 暴露 snapshot / rollback action,就可以把回滚能力也变成服务 API。
这个架构也不局限于 Redis。只要为某个有状态服务准备好模板,例如 Redis、MySQL、Postgres、Nginx、消息队列或向量数据库,并在 gateway 配置中声明服务名、模板 ID 和端口,CubeSandbox 提供的就是对应的服务实例。换句话说,Cube 提供的是一套"模板化有状态服务"的生命周期底座:快速创建、克隆分支、保存 checkpoint、失败回滚、最终销毁。
架构关系如下:
如何执行:
cd examples/cube-service-gateway
cp config.example.json config.json
python3 server.py config.json
# 另一个终端中创建 Redis 服务
python3 client.py create redis
# 拿到 sandbox_id 后克隆这个 Redis 服务
python3 client.py clone <sandbox_id>配置中的关键映射是:
{
"templates": {
"redis": {
"template_id": "tpl-e48c5119a5714f3aa7853779",
"service_port": 6379
},
"nginx": {
"template_id": "tpl-13df4e20518c465a90c1d7e1",
"service_port": 80
}
}
}执行结果摘录:
$ python3 client.py create redis
{
"sandbox_id": "0f067f5e61ad477fa32d0df45434d51d",
"name": "redis",
"service_port": 6379,
"endpoint": "10.206.0.4:20006"
}
elapsed: 77.1 ms
$ redis-cli -h 10.206.0.4 -p 20006
10.206.0.4:20006> set name rony
OK
10.206.0.4:20006> get name
"rony"
$ python3 client.py clone 0f067f5e61ad477fa32d0df45434d51d
{
"sandbox_id": "40e42e1e7fe34ae4b995271d39166b2e",
"name": "redis",
"service_port": 6379,
"endpoint": "10.206.0.4:20008"
}
elapsed: 314.2 ms
$ redis-cli -h 10.206.0.4 -p 20008
10.206.0.4:20008> keys *
1) "name"
10.206.0.4:20008> get name
"rony"结果说明:create redis 在 77.1ms 内返回一个可访问 Redis;写入 name=rony 后,再 clone 出来的 Redis 仍然能读到 "rony",clone 耗时 314.2ms。这说明 Redis 的数据状态被一并复制到了新实例中。对 Agent 来说,这不只是"拉起一个缓存服务",而是获得了一个可以从任意已知状态继续分叉的 Redis 工作空间。
注:clone 出来的实例会继承源实例的网络连接,但是这些网络连接再也无法收发包,最好显式处理残留的网络连接或者等待它们超时。
更进一步,这种模式可以推广到其他有状态服务,只需简单两步:
- 参照自定义镜像,构建一个包含自己服务的模版,记录下模版 ID:
tpl-abcdeeff - 编辑 cube-service-gateway 的配置文件,加上新构建的服务模版:
{
"templates": {
"redis": {
"template_id": "tpl-e48c5119a5714f3aa7853779",
"service_port": 6379
},
"new_service": {
"template_id": "tpl-abcdeeff",
"service_port": <service-port>
}
}
}服务本身仍然是传统软件,但接入 CubeSandbox 后,传统软件生命周期变成了 Agent 友好的:极速拉起、带状态快速克隆、失败回滚、任务结束后销毁。
结语
Agent 对软件服务的要求,本质上是状态生命周期的变化。过去我们关注服务是否稳定运行;现在还要关注它能否被快速创建、能否从任意状态分支、能否在失败后回滚、能否低成本地大量存在。
Neon、Turso、Upstash 说明,各类软件服务已经开始围绕 Agent 的工作方式重构产品形态。而 CubeSandbox 更进一步:它把快速启动、快照、克隆、回滚这些能力下沉到通用运行环境里,使各种传统服务也能轻易获得类似"分支"和"时间机器"的能力。
欢迎关注 CubeSandbox 项目:https://github.com/TencentCloud/CubeSandbox